一、交集
1、有两个有序整数集合A和B,写一个函数找出它们的交集?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import java.util.HashSet; import java.util.Set; public class bingji { public static void main(String[] args) { int []a1=new int[100000]; for(int i=10;i<a1.length;i++){ a1[i]=i+10; } int []a2=new int[200000]; for(int i=10;i<a2.length;i++){ a2[i]=i+20; } long begin = System.currentTimeMillis(); Set<Integer> set1 = setMethod(a1, a2); long end = System.currentTimeMillis(); System.out.println(end - begin);// } private static Set<Integer> setMethod(int[] a, int[] b) { Set<Integer> set = new HashSet<Integer>(); Set<Integer> set2 = new HashSet<Integer>(); for (int i = 0; i < a.length; i++) { set.add(a[i]); } for (int j = 0; j < b.length; j++) { if (!set.add(b[j])){ set2.add(b[j]); } return set2; } } |
Set add 方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
boolean add(E e) 如果 set 中尚未存在指定的元素,则添加此元素(可选操作)。更确切地讲,如果此 set 没有包含满足 (e==null ? e2==null : e.equals(e2)) 的元素 e2,则向该 set 中添加指定的元素 e。如果此 set 已经包含该元素,则该调用不改变此 set 并返回 false。结合构造方法上的限制,这就可以确保 set 永远不包含重复的元素。 上述规定并未暗示 set 必须接受所有元素;set 可以拒绝添加任意特定的元素,包括 null,并抛出异常,这与 Collection.add 规范中所描述的一样。每个 set 实现应该明确地记录对其可能包含元素的所有限制。 指定者: 接口 Collection<E> 中的 add 参数: e - 要添加到 set 中的元素 返回: 如果 set 尚未包含指定的元素,则返回 true 抛出: UnsupportedOperationException - 如果此 set 不支持 add 操作 ClassCastException - 如果指定元素的类不允许它添加到此 set NullPointerException - 如果指定的元素为 null 并且此 set 不允许 null 元素 IllegalArgumentException - 如果指定元素的某些属性不允许它添加到此 set |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
private static Set<Integer> forMethod(int[] a, int[] b) { Set<Integer> set = new HashSet<Integer>(); int i = 0, j = 0; while (i < a.length && j < b.length) { if (a[i] < b[j]) i++; else if (a[i] > b[j]) j++; else{ set.add(a[i]); i++; j++; } } return set; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
private static int[] intersect (int[]a,int[]b){ if (a[0] > b[b.length - 1] || b[0] > a[a.length - 1]) { return new int[0]; } int[] intersection = new int[Math.max(a.length, b.length)]; int offset = 0; for (int i = 0, s = i; i < a.length && s < b.length; i++) { //首先判断两个数组的值大小,如果a[i]中值比b[s]大,则执行;若非,则不执行 while (a[i] > b[s]) { s++; } //i=20,s=10跳进来 if (a[i] == b[s]) { intersection[offset++] = b[s++]; } //去除重复值 while (i < (a.length - 1) && a[i] == a[i + 1]) { i++; } } if (intersection.length == offset) { return intersection; } int[] duplicate = new int[offset]; System.arraycopy(intersection, 0, duplicate, 0, offset); return duplicate; } |
|
1 2 3 |
方法一用时:73 毫秒 方法二用时:20 毫秒 方法三用时:2 毫秒 |
扩展:A、B两个整数集合,设计一个算法求他们的交集,尽可能的高效。
1)排序法:对集合A和集合B进行排序(升序,用快排,平均复杂度O(N*logN)),设置两个指针p和q,同时指向集合A和集合B的最小值,不相等的话移动*p和*q中较小值的指针,相等的话同时移动指针p和q,并且记下相等的数字,为交集的元素之一,依次操作,直到其中一个集合没有元素可比较为止。
缺点:使用的排序算法不当,会耗费大量的时间,比如对排好序的逆序集合使用快排, 时间复杂度是O(N2)。快排的平均复杂度是O(N*logN),对排好序的集合做查找操作,时间复杂度为O(N),当然这种算法肯定比遍历要快多了。
该函数接受两个指向const void参数的指针,并返回一个int。在typedef中使用指向void的指针将允许我们为所有的比较函数使用相同的typedef。
真实的函数接受两个指向真实结构的指针(而不是指向void的指针)作为其参数。编译器将允许互换指向const void的指针与指向真实对象的指针。
|
1 |
typedef int(*CompFunc)(const void *,const void *); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#include <stdio.h> #include <stdlib.h> #include <vector> using namespace std; #define M 8 #define N 5 typedef int(*CompFunc)(const void *,const void *); int cfunc(int *a,int *b){ return (*a)-(*b); } void forMethod(int A[],int B[],vector<int>&result){ int i=0,j=0; while(i<M&&j<N){ if(A[i]<B[j]) i++; else if(A[i]>B[j]) j++; else{ result.push_back(A[i]); i++; j++; } } } int _tmain(int argc, _TCHAR* argv[]){ int A[] = {-1, 2 ,39 ,10, 6, 11, 188, 10}; int B[] = {39 ,8 , 10, 6, -1}; //对数组A和数组B进行快排 qsort(A, M, sizeof(int), (CompFunc)cfunc); qsort(B, N, sizeof(int), (CompFunc)cfunc); vector<int>result; forMethod(A,B,result); // int result[M > N ? M : N];//保存交集的结果 return 0; } |
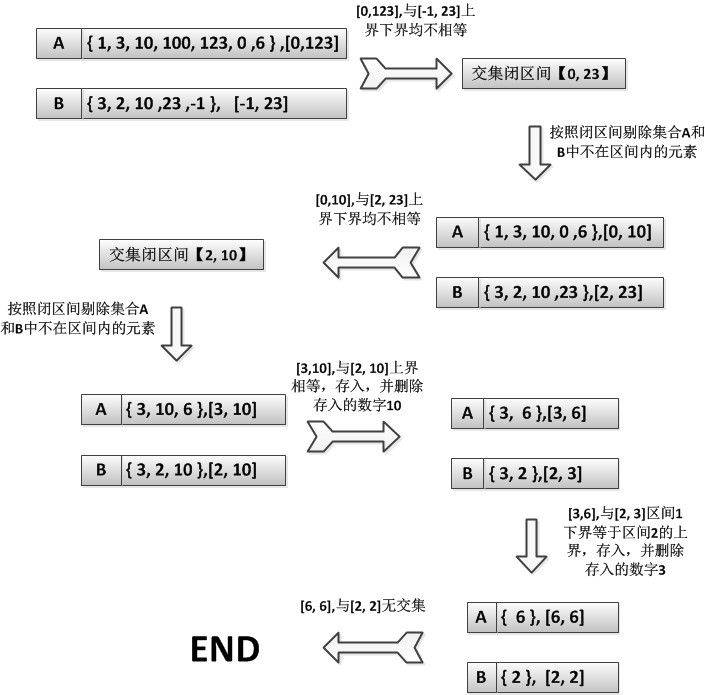
2)集合压缩思想:(转载)
假设集合A的最大值和最小值分别为MaxInA,MinInA;假设集合B的最大值和最小值分别为MaxInB,MinInB;那么集合A的所有元素一定在闭区间【MinInA, MaxInA】里面,集合B的所有元素一定在闭区间【MinInB, MaxInB】里面,从这两个集合里面我们可以作如下判断:(集合A和集合B都在链表中!)
1. 若MinInA == MinInB或者MaxInA == MaxInB,那么MinInA 或者MaxInA (相等的那个数)就一定在交集里面,存入交集(可以用数组存),删除链表中相应的结点;若不想等则跳到第3步;
2. 重新找到集合A和B中的最大值和最小值MinInA 、MaxInA 、MinInB、MaxInB;跳回第1步;
3. 更新区间(交集的区间),区间的更新如下:区间下界为Lower = max(MinInA, MinInB),上届为Upper = min(MaxInA , MaxInB),那么剩下的交集一定在闭区间【Lower ,Upper】里面,按照这个区间来剔除掉集合A和集合B中不符合条件的元素,剔除结束后,若其中一个集合为空,跳到第4步,否则返回第2步;
4. 程序结束,退出!
这种适用于集合里面数值比较散乱,最大值最小值差值比较大的情况!算法的思想在于不断减小搜索的范围。
扩展:当A,B是很大的集合时,比如A是一亿个ip地址,B是一个黑名单,但也有上百万个ip地址,单机内存不足以装下A,B。用布隆过滤器的思路去解?
2、文件中有10G个整数,乱序排列,要求找出中位数。(内存限制为 2G)
中位数:数据排序后,位置在最中间的数值。即将数据分成两部分,一部分大于该数值,一部分小于该数值。
中位数的位置:当样本数为奇数时,中位数=(N+1)/2 ; 当样本数为偶数时,中位数为N/2与1+N/2的均值(那么10G个数的中位数,就第5G大的数与第5G+1大的数的均值了)。
桶排序思想(好像就是计数排序的思想):假定输入数据为 ,必须只由小于M的正整数组成。使用一个大小为M的称为count的数组,初始为0。count有M个单元(或称桶),这些桶初始化为空。当读
,必须只由小于M的正整数组成。使用一个大小为M的称为count的数组,初始为0。count有M个单元(或称桶),这些桶初始化为空。当读 时,
时,![count[A_{i}]](http://ramsey16.net/wp-content/plugins/latex/cache/tex_15f09f573e40c1dac8bb476509f55f04.gif) 加1。在所有输入数据读入后,打印输出。算法用时
加1。在所有输入数据读入后,打印输出。算法用时 。
。
回到这题的思路:32位机下unsigned int和int均占4个byte。将整形的每1byte作为一个关键字,也就是说一个整形可以拆成4个keys,而且最高位的keys越大,整数越大。如果高位keys相同,则比较次高位的keys。整个比较过程类似于字符串的字典序。(Trie树,看前缀)基于字节的桶排序!!!
1.把10G整数每2G读入一次内存,然后一次遍历这536,870,912个数据(2GB/4B)。每个数据用位运算">>"取出最高8位(31-24)。这8bits(0-255)最多表示255个桶,那么可以根据8bit的值来确定丢入第几个桶。最后把每个桶写入一个磁盘文件中,同时在内存中统计每个桶内数据的数量,自然这个数量只需要255个整形空间即可。
1.1 代价:(1) 10G数据依次读入内存的IO代价(这个是无法避免的,CPU不能直接在磁盘上运算)。(2)在内存中遍历536,870,912个数据,这是一个O(n)的线性时间复杂度。(3)把255个桶写会到255个磁盘文件空间中,这个代价是额外的,也就是多付出一倍的10G数据转移的时间。
2.根据内存中255个桶内的数量,计算中位数在第几个桶中。很显然,2,684,354,560 (10G int) 个数中位数是第1,342,177,280个。假设前127个桶的数据量相加,发现少于1,342,177,280,把第128个桶数据量加上,大于1,342,177,280。说明,中位数必在磁盘的第128个桶中。而且在这个桶的第1,342,177,280-N(0-127)个数位上。N(0-127)表示前127个桶的数据量之和。然后把第128个文件中的整数读入内存。(平均而言,每个文件的大小估计在10G/128=80M左右,当然也不一定,但是超过2G的可能性很小)。
2.1.代价:(1)循环计算255个桶中的数据量累加,需要O(M)的代价,其中m<255。(2)读入一个大概80M左右文件大小的IO代价。
注意,变态的情况下,这个需要读入的第128号文件仍然大于2G,那么整个读入仍然可以按照第一步分批来进行读取。
3.继续以内存中的整数的次高8bit进行桶排序(23-16)。过程和第一步相同,也是255个桶。
4.一直下去,直到最低字节(7-0bit)的桶排序结束。这个时候完全可以在内存中使用一次快排就可以了。
分析:整个过程的时间复杂度在O(n)的线性级别上(没有任何循环嵌套)。但主要时间消耗在第一步的第二次内存-磁盘数据交换上,即10G数据分255个文件写回磁盘上。一般而言,如果第二步过后,内存可以容纳下存在中位数的某一个文件的话,直接快排就可以了。
二、并查集(不相交集合数据结构)
一些应用涉及将n个不同的元素分成一组不相交的集合。需要两种特别的操作:寻找包含给定元素的唯一集合和合并两个集合。
并查集就是能够实现若干个不相交集合,较快的合并和判断元素所在集合的操作。不相交集合:一个不相交集合维护了一个不相交动态集合 我们用一个代表标识每一个集合,它是这个集合的某个成员。我们不关心哪个成员作为代表,仅关心2次查询这个集合时放回结果应该相同(如果我们不修改集合)。
我们用一个代表标识每一个集合,它是这个集合的某个成员。我们不关心哪个成员作为代表,仅关心2次查询这个集合时放回结果应该相同(如果我们不修改集合)。
并查集主要就有三个方法:
|
1 2 3 |
make-set(x)建立一个新集合唯一元素就是x,因为是不相交集合所以x不会出现在其他集合中。 union(x,y)将包含x和y的2个动态集合合并成一个新集合。 find-set(x)返回一个指针,这个指针指向包含x的集合的代表。 |
应用:一些常见的用途有求连通子图、求最小生成树的 Kruskal 算法和求最近公共祖先(Least Common Ancestors, LCA)等。
形象的来说明上述概念:
两个不相交集合,a集合的代表就是a而e集合代表就是e。我们在a树上查找b则返回a而查找c也返回a,说明b与c在同一结合上;而查找f返回e,说明c与f是在两个集合上,它们两个是不相交的。union操作使得一棵树的根指向另外一颗树的根。

按秩合并(union by rank):对于每个结点,维护一个秩,表示该结点高度的一个上界。加入rank[N]来记录每个节点的秩(即树的高度),并按秩进行合并,可避免合并时的最糟糕情况,(树形为一条直线)(某个数在一个集合中的秩是指该集合中小于或等于该数的元素的个数,但在这里不是这个意思。)简单的说,就是总是将比较矮的树作为子树,添加到较高的树中。(具有较小秩的根指向具有较大秩的根)

按路径压缩:使查找路径中的每个结点直接指向代表节点(根)。路径压缩并不改变任何结点的秩。

每个元素都指向自己的父节点也就是自己。这种方式每个节点都指向自己的上一节点。而只有代表节点指向的是自己。树的节点表示集合中的元素,指针表示指向父节点的指针,根节点的指针指向自己,表示其没有父节点。沿着每个节点的父节点不断向上查找,最终就可以找到该树的根节点,即该集合的代表元素。
静态链表:比较类似于内存池,它会预先分配一个足够长的数组,之后链表节点都会保存在这个数组里,这样就不需要频繁的进行内存分配了。
假设使用一个足够长的数组来存储树节点,
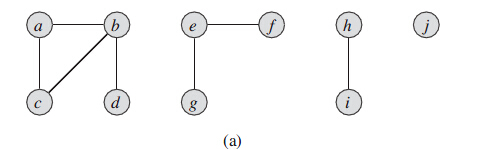
并查集的应用之一就是确定无向图的连通分量。图(a)表示一个包含4个连通分量的图。

问题:某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。问最少还需要建设多少条道路?
|
1 2 3 4 5 6 7 8 9 |
每个测试用例的第1行给出两个正整数,分别是城镇数目N ( < 1000 )和道路数目M;随后的M行对应M条道路,每行给出一对正整数,分别是该条道路直接连通的两个城镇的编号。为简单起见,城镇从0到N-1编号。 4 2 0 2 3 2 3 3 0 1 0 2 1 2 |
分析:首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
第一行告诉你,一共有4个点,2条路。下面两行告诉你,0、2之间有条路,3、2之间有条路。那么整幅图就被分成了0-2-3和1两部分。只要再加一条路,把1和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
#include <stdio.h> #include <stdlib.h> #include <vector> using namespace std; const int MAXSIZE=1050; int uset[MAXSIZE];//记录了每个结点的上级(父结点)是谁 int noderank[MAXSIZE]; void makeset(int size){ //所有的节点都是不相交集合,每个元素都是一个单元素集合,代表节点都指向自己。 for (int i = 0; i < size; i++) { uset[i]=i; } for(int i=0;i<size;i++) noderank[i]=0; } //路径压缩,令查找路径上的每个结点都指向根节点 int findset_digui(int x){ if (x != uset[x]) uset[x] = findset_digui(uset[x]); return uset[x]; } //查找根节点 int findset_iter(int x){ int r=x,t; while(uset[r]!=r) //返回根节点 r r=uset[r]; //路径压缩 while(x!=r){ t=uset[x]; //在改变上级之前用临时变量 t 记录下他的值 uset[x]=r; //把上级改为根节点 x=t; } return x; } //按秩合并 void unionset(int x,int y){ if((x=findset_iter(x))==(y=findset_iter(y)))return; if(noderank[x]>noderank[y]) uset[y]=x; else{ uset[x]=y; if(noderank[x]==noderank[y])noderank[y]++; } } //判断x y是否连通,如果已经连通,就不用管了;如果不连通,就把它们所在的连通分支合并起, void unionset1(int x,int y){ int fx=findset_iter(x),fy=findset_iter(y); if(fx!=fy) uset[fx]=fy; } int _tmain(int argc, _TCHAR* argv[]){ int N,M,a,b,i,j,ans; while(scanf("%d%d",&N,&M)&&N){ makeset(N);//初始化 对于这道题目来说,一开始都是一个个独立的节点,所以可以这样粗暴的union for(i=1;i<=M;i++){ scanf("%d%d",&a,&b); unionset1(a,b); } for(i=0;i<N;i++){ //标记根结点 noderank[findset_iter(i)]=1; } //看有几个没有连接的结点,那么需要的变数就等于ans-1 for(ans=0,i=0;i<N;i++) if(noderank[i]) ans++; printf("%d\n",ans-1); //对全局数组清零 memset(noderank,0,sizeof(noderank)); memset(uset,0,sizeof(uset)); } return 0; } |
参考:
1)http://www.cnblogs.com/gw811/archive/2012/10/15/2724100.html
2)http://www.cnblogs.com/bestDavid/p/ExaminationTencent.html
3)http://blog.csdn.net/idlear/article/details/19556587
4)http://blog.csdn.net/dellaserss/article/details/7724401 非常可爱的讲解
5)http://www.tuicool.com/articles/7juuQf
1、请设计一个排队系统,能够让每个进入队伍的用户都能看到自己在 中所处的位置和变化。队伍可能随时有人加入和退出,当有人退出影响到用户的位置排名时需要即时反馈到用户。
第一题应该不是让写算法,而是观察者模式的实现:
有退出进行通知,当B退出,执行状态改变,进行通知。至于通知的信息,很简单:假如A的排名在B之前,A则只接受B退出的消息;若在B之后,则接受退出和排名变化的消息。有人加入系统,通知所有用户信息通知和排名(+1)变化。
单链表看起来是最好的,每次有人退出,则先从队伍开头head找到他的位置,作为标记记下来,在单链表中移除掉该人后,根据标记通知该标记后面的人(因为前面人不受影响)。其实这道题目出的很烂,真正做项目时,肯定设计为CS接口,服务器发消息给后面的人好了。Client有人退出=》服务器移除该用户=》服务器通知受影响的人=》客户端收到消息。跟观察者有毛关系
因为不存在有插队的情况,则每个人加入进来可以知道当前共有多少个人在排队了,新加入进来就给这人位置与进入时间及编号(自增),每个人退出也会记录这些信息。
当要查某人所在位置时,可通过本身进入的编号,位置与时间,及这段时间退出的人,则可以准确算出位置,但有一点注意是,每查一个人的位置后,就要更新下这个人的位置和时间,个人感觉这样很高效