背景:在多用户环境中,操作系统调度程序必须决定在若干进程中运行哪个进程。一般一个进程只能被允许运行一个固定的时间片。一种算法是使用队列。开始时作业被放到队列的末尾,调度程序将反复提取队列中的第一个作业并运行它,直到运行完毕或者该作业的时间片用完,若作业未被运行完毕就将其放到队列的末尾。显然对于一些很短的作业由于一味等待运行而要花费很长的时间去处理。一般说来,短的作业要尽可能快的结束,因此在已经被运行的作业中这些短作业应该拥有优先权。同时,做些作业虽然不短小但很重要,也应该拥有优先权。
优先队列(priority queue)是一种用来维护由一组元素构成的集合S的数据操作,其中每个元素都有一个相关的值,称为key。
一个最大优先队列支持以下操作:
- INSERT(S,x):把元素x插入集合S中。等价于
 (相当于enqueue(入队))
(相当于enqueue(入队)) - MAXIMUM(S):返回S中具有最大关键字的元素
- DELETE-MAX(S):去掉并返回S中的具有最大键字的元素 (相当于dequeue(入队))
- INCREASE-KEY(S,x,k):将元素x的关键字值增加到k,假设k的值不小于x的关键字值
最大优先队列的应用:共享计算机系统的作业调度。最大优先队列记录将要执行地各个作业(Job)以及它们之间的相对优先级。当一个作业完成或者被中断后,调度器调用EXTRACT-MAX从所有等待的作业中,选出具有最高优先级的作业来执行。在任何时候调度器可以调用INSERT把一个新作业加入到队列中来。
一个最小优先队列支持以下操作:
- INSERT(S,x):把元素x插入集合S中。等价于 (相当于enqueue(入队))
- MINIMUM(S):返回S中具有最小关键字的元素
- DELETE-MIN(S):去掉并返回S中的具有最大键字的元素 (相当于dequeue(入队))
- DECREASE-KEY(S,x,k):将元素x的关键字值增加到k?,假设k的值不小于x的关键字值

最小优先队列的实现方法
1)使用简单链表。在表头以O(1)执行插入操作,以 遍历该链表以删除最小元
遍历该链表以删除最小元
2)让表始终保持排序状态:这使得插入代价为,而EXTRACT-MIN(S)为
3)二叉查找树:对于这两种操作的平均运行时间均为 。尽管插入是随机的,但是删除不是。删除最小元,会反复出去左子树中的结点,破坏树平衡,使得右子树加重。右子树是随机的。最坏情况下,EXTRACT-MIN(S)将左子树删空,右子树拥有的元素是其应有的两倍。当然,通过使用AVL平衡树,可以将界变成最坏情形的界。(这句话不太懂)
。尽管插入是随机的,但是删除不是。删除最小元,会反复出去左子树中的结点,破坏树平衡,使得右子树加重。右子树是随机的。最坏情况下,EXTRACT-MIN(S)将左子树删空,右子树拥有的元素是其应有的两倍。当然,通过使用AVL平衡树,可以将界变成最坏情形的界。(这句话不太懂)
最小二叉堆,同最大二叉堆性质相似,参见排序算法四(堆排序)。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
//宏定义,可以定义在类里面,也可以定义在类外面,编译器首先替换宏,然后再是编译过程 #define LEFT(i) i<<1 #define RIGHT(i) (i<<1)+1 #define PARENT(i) i>>1 template<typename T>class BinaryHeap{ public: explicit BinaryHeap(int capacity=100){ currentsize=0; array.resize(capacity);//注意,这里不要用reserve,resize会分配空间,不然会报错 } explicit BinaryHeap(const vector<T>&items); bool IsEmpty()const; const T&findMin()const; void INSERT(const T&x); void DELETE_MIN(); void DELETE_MIN(const T&minItem); void MAKEEMPTY(); private: int currentsize; vector<T> array;//位置0是一个限位器 void BUILDHEAP(); int MINHEAPFIY(int hole);(上滤操作) void SWAP(int *a,int *b){ int temp=*a; *a=*b; *b=temp; } }; |
INSERT(S,x):在下一个空闲位置创建一个空穴,如果x可以放在空穴上而不破坏堆序,则插入完成。否则,进行上滤操作。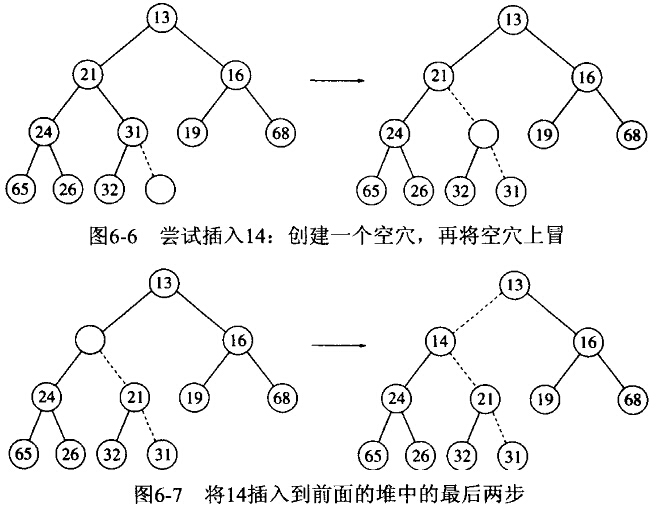
|
1 2 3 4 5 6 7 8 9 10 |
template<typename T>void BinaryHeap<T>::INSERT(const T&x){ if(currentsize==array.size()-1) array.resize(array.size()*2); int hole=++currentsize;//vector第0个位置不插入元素 //这就是一个上滤的过程 for(;hole>1&&x<array[hole/2];hole/=2) array[hole]=array[hole/2]; array[hole]=x;//注意,这里的hole值会发生改变 } |
|
1 2 3 4 5 6 7 8 9 10 |
BinaryHeap<int> binaryheap; binaryheap.INSERT(21); binaryheap.INSERT(13); binaryheap.INSERT(16); binaryheap.INSERT(24); binaryheap.INSERT(31); binaryheap.INSERT(19); binaryheap.INSERT(68); binaryheap.INSERT(65); binaryheap.INSERT(26); |
显然这种上滤的方式非常有效,如果一个元素上滤d层,只需要d+1次赋值。而反复实施交换操作,每一次交换需要3条赋值语句,那么就需要3d次赋值。
如果插入的元素是新的最小元从而一直上滤到根处,那么这种插入的时间为。平均来看,这种上滤终止得要早;已经证明,执行一次插入平均需要2.607次比较,因此INSERT将元素平均上移1.607层。
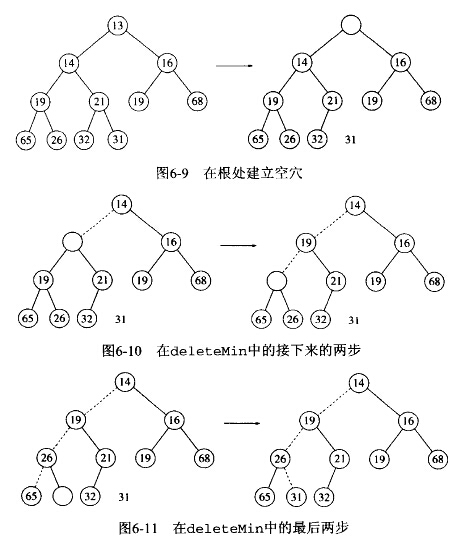
DELETE-MIN(S):当删除一个最小元时,要在根节点建立一个空穴。由于现在堆少了一个元素,因此堆中最后一个元素x必须移动到该堆的某个地方。将空穴的两个儿子中的较小者移入空穴,这样就把空穴下移一层。重复该步骤直到x可以放入空穴中。
当堆中存在偶数个元素时,将出现一个结点只有一个儿子的情况,我们必须以结点不总有两个儿子为前提。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
template<typename T>void BinaryHeap<T>::DELETE_MIN(){ if(IsEmpty()) return; int temp=currentsize--; array[1]=array[temp];//先把根节点替换为最后一个元素,然后对它进行下滤操作 array[temp]=0; Percolate_Down(1); } template<typename T>void BinaryHeap<T>::DELETE_MIN(const T&minItem){ if(IsEmpty()) return; minItem=array[1]; int temp=currentsize--; array[1]=array[temp];//先把根节点替换为最后一个元素,然后对它进行下滤操作 array[temp]=0; Percolate_Down(1); } template<typename T>void BinaryHeap<T>::Percolate_Down(int hole){ int child; T temp=array[hole]; for(;hole*2<=currentsize;hole=child){ child=hole*2;//左孩子 if(child!=currentsize&&array[child+1]<array[child])//较小儿子 child++; if(array[child]<temp) array[hole]=array[child]; else break; } array[hole]=temp; } |
首先我们建立一个这样的堆:13,14,16,19,17,19,68,65,26,31,31共11个元素。调用DELETE_MIN()后current_size变为10,我们将最后一个元素31放在第一个元素位置。然后进行下滤操作。这时候堆中有10个元素,即将出现一个结点只有一个儿子
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
BinaryHeap<int> binaryheap; binaryheap.INSERT(13); binaryheap.INSERT(14); binaryheap.INSERT(16); binaryheap.INSERT(19); binaryheap.INSERT(17); binaryheap.INSERT(21); binaryheap.INSERT(19); binaryheap.INSERT(68); binaryheap.INSERT(65); binaryheap.INSERT(26); binaryheap.INSERT(32); binaryheap.INSERT(31); binaryheap.DELETE_MIN(); |
下滤完毕,未将元素填入空穴时,

将元素填入空穴后, 完成删除操作

算法复杂度:最坏情况运行时间为,平均而言,被放到根处的元素几乎下滤到堆的底层,即它所来自的那层。所以平均运行时间为 。
BULIDHEAP(S):将N项以任意顺序放入树中,并保持结构特性。
用自顶向下的方法利用过程Percolate_Down把一个大小为n=A.length的数组A[1,...,n]转换为最小堆。子数组A(⌊n/2⌋+1,...,n)中的元素为叶结点。对树中的其他结点都调用一次Percolate_Down。

注意,这里要用size_t,否则会有warning C4018: '<' : signed/unsigned mismatch。
|
1 2 3 4 5 6 |
template<typename T>BinaryHeap<T>::BinaryHeap(const vector<T>&items) :array(items.size() + 10), currentsize(items.size()){ for (size_t i = 0; i<items.size(); i++){ array[i + 1] = items[i]; } BUILDHEAP(); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
template<typename T>void BinaryHeap<T>::BUILDHEAP(){ //注意,不能从1到curretn_size/2,必须保证下面的全部为最小堆 for(int i=currentsize/2;i>0;i--){ Percolate_Down(i); } } int _tmain(int argc, _TCHAR* argv[]){ const vector<int> items = { 150, 80, 40, 30, 10, 70,110,100,20,90,60,50,120,140,130 };//VS2013初始化 BinaryHeap<int> binaryheap(items); return 0; } |
插播一条定理: 包含 个结点且高为h的理想二叉树的结点的高度和为
个结点且高为h的理想二叉树的结点的高度和为 。
。
证明:容易看出,该树由高度h上的1个结点,高度h-1上的2个结点以及在一般高度h-i上的 个结点组成。则所有结点的高度和为
个结点组成。则所有结点的高度和为


优先队列的应用:
1、首先看一个选择问题:设有一组N个数,要确定其中第k个最大者。
1)将这些元素读入数组并将它们排序,返回需要的元素。假设采用最简单的排序算法,运行时间为
2)将k个元素读入一个数组并将其排序,这些元素中的最小者在第k个位置上。依次处理其余的元素,将这个元素与数组中第k个元素进行比较,如果元素大,那么将第k个元素删除,而将这个元素放在其余的k-1个元素间的正确的位置上(插入排序)。当算法结束时,第k个位置上的元素即正确答案。该方法的运行时间为 。每个元素会和k个元素进行比较。
。每个元素会和k个元素进行比较。
 ,那么这两种算法均为。对于任意的k,我们可以求解对称的问题找出第(N-k+1)个最小的元素。
,那么这两种算法均为。对于任意的k,我们可以求解对称的问题找出第(N-k+1)个最小的元素。
运用最小优先队列,首先只考虑找出第k个最小的元素。
将N个元素读入一个数组,对该数组应用BUILDHEAP(),最后执行K次DELETE_MIN(const T&minItem),最后从该堆提取的元素就是需要的答案。
BUILDHEAP()的最坏情形是 ,每次执行DELETE_MIN(const T&minItem)为。所以为
,每次执行DELETE_MIN(const T&minItem)为。所以为 。如果
。如果 ,那么运行时间取决于BUILDHEAP()操作即。对于大的k值,运行时间为
,那么运行时间取决于BUILDHEAP()操作即。对于大的k值,运行时间为 。如果,那么运行时间为
。如果,那么运行时间为 。
。
2、事件模拟
首先看一道腾讯的笔试题:请设计一个排队系统,能够让每个进入队伍的用户都能看到自己在队列中所处的位置和变化,队伍可能随时有人加入和退出;当有人退出影响到用户的位置排名时需要及时反馈到用户。
二项队列
一个二项队列不是一棵堆序的树,而是堆序的树的集合,称为森林(forest)。堆序树中的每一棵都是有约束的形式,叫做二项树(binomial tree)。每一个高度上至多存在一棵二项树。高度为0的二项树是一棵单结点树;高度为k的二项树 通过将一棵二项树
通过将一棵二项树 附接到同一棵二项树的根上而构成。
附接到同一棵二项树的根上而构成。
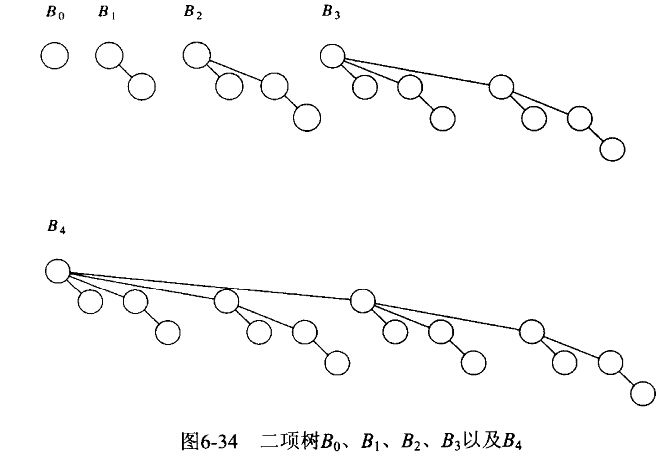
如上图,二项树由一个带有儿子 的根组成。高度为k的二项树恰好有
的根组成。高度为k的二项树恰好有 个结点(树高为4,有2^{4}=16个结点),而在深度d处的结点数是二项系数
个结点(树高为4,有2^{4}=16个结点),而在深度d处的结点数是二项系数
|
1 2 3 4 5 6 7 |
//深度是指所有结点中最深的结点所在的层数。 int TreeDepth(BinaryTreeNode*m_pRoot){ if(m_pRoot==nullptr)return 0; int nLeft=TreeDepth(m_pRoot->m_pLeft); int nRight=TreeDepth(m_pRoot->m_pRight); return (nLeft>nRight)?(nLeft+1):(nRight+1); } |
深度为1(叶结点)处有4C1=4个结点,深度为2处有4C2=6个结点,深度3处有4C3=4个结点,深度4处有4C4=1个结点。
二叉树转换为森林
假如一棵二叉树的根节点有右孩子,则这棵二叉树能够转换为森林,否则将转换为一棵树。
(1)从根节点开始,若右孩子存在,则把与右孩子结点的连线删除。再查看分离后的二叉树,若其根节点的右孩子存在,则连线删除…。直到所有这些根节点与右孩子的连线都删除为止。
(2)将每棵分离后的二叉树转换为树。

http://www.cnblogs.com/zhuyf87/archive/2012/11/04/2753950.html
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
http://dsqiu.iteye.com/blog/1714961