分治思想
分治模式在每层递归时有三个步骤:
分解原问题为若干个子问题,这些子问题是原问题的规模较小的实例。
解决这些子问题,递归地求解各子问题。然而,若这些子问题的规模足够小,则直接求解。
合并这些子问题的解成原问题的解。
一、快速排序
思想:采用分治的思想。按照元素的值对其进行划分。
分解:对于子数组A[p,...,r]被划分为两个(可能空)子数组A[p,...q-1]和A[q+1,....,r],使得A[p,...q-1]中的每一个元素都小于等于A[q],而A[q]也小于等于A[q+1,....,r]中的每个元素。
总是选择一个x=A[r]作为主元,并围绕它来划分子数组A[p,...,r]。对于这样一个子数组,由连续的三段组成:一段为已知小于x的元素,一段为已知大于x的元素,还有一段未同x比较过的元素。注意,这些段可以为空。显然,当算法开始时,前两段常常是空段。
伪代码:

循环不变量:循环体的每一次迭代开始时,对于任意数组下标k,有:
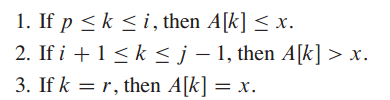
分析PARTION操作:PARTION的一次迭代会有两种情况:(a)如果A[j]>x,则j值加1,从而使循环不变量继续保持;(b)如果A[j]<=x,则将下标i的值加1,交换A[i]和A[j],再将j值加1.
再PARTION的最后一步操作,是将主元x与最左的大于x的元素进行交换,就可以将主元移到它在数组中的正确位置上,并返回主元的新下标。那么,这个值就将数组分成了两个子数组。
示例:
代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
void swap(int *a,int *b){ int temp=*a; *a=*b; *b=temp; } int PARTION(int A[],int p,int r){ int x=A[r];//总是选择一个x=A[r]作为主元 int i=p-1; for(int j=p;j<=r-1;j++){ if(A[j]<=x){ i=i+1; swap(A[i],A[j]); } } swap(A[i+1],A[r]); return i+1; } void QuickSort(int A[],int p,int r){ int q=0; if(p<r){ q=PARTION(A,p,r); QuickSort(A,p,q-1); QuickSort(A,q+1,r); } } int _tmain(int argc, _TCHAR* argv[]){ int A[8]={2,8,7,1,3,5,6,4}; QuickSort(A,0,7); for(int i=0;i<8;i++){ cout<<A[i]<<","; } cout<<endl; system("pause"); return 0; } |
相关问题:
1)当数组A[p,...,r]中的元素都相同时,PARTION返回的q值是多少?修改PARTITION,使得当数组A[p,...,r]中所有元素都相同时, 。(7.1-2)
。(7.1-2)
解答:返回的q值为r。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
//counting the number of comparisons in which A[j]=A[r] and then subtracting half that number from the pivot index. int ModifyPARTION(int A[],int p,int r){ int pivot_value=A[r];//总是选择一个x=A[r]作为主元 int i=p-1; int value=0; int repetitions=0; for(int j=p;j<=r-1;j++){ value=A[j]; if(value==pivot_value) repetitions+=1; if(A[j]<=pivot_value){ i=i+1; swap(A[i],A[j]); } } swap(A[i+1],A[r]); return i-repetitions/2; } void QuickSort(int A[],int p,int r){ int q=0; if(p<r){ q=ModifyPARTION(A,p,r); QuickSort(A,p,q-1); QuickSort(A,q+1,r); } } int _tmain(int argc, _TCHAR* argv[]) { int A[8]={2,2,2,2,2,2,2,2}; QuickSort(A,0,7); |
Python版本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def partition(numbers, start = 0, end = None): last = end - 1 if end else len(numbers) - 1 pivot_value = numbers[last] pivot = start repetitions = 0 for i in range(start, last): value = numbers[i] if value == pivot_value: repetitions += 1 if value <= pivot_value: numbers[pivot], numbers[i] = numbers[i], numbers[pivot] pivot += 1 numbers[pivot], numbers[last] = numbers[last], numbers[pivot] return pivot - repetitions // 2 def quicksort(numbers, start = 0, end = None): end = end if end else len(numbers) if start < end - 1: pivot = partition(numbers, start, end) quicksort(numbers, start, pivot) quicksort(numbers, pivot + 1, end) |
2)证明:在规模为n的子数组上,PARTION的时间复杂度为 。
。
证:There is a for statement whose body executes r-1-p= times. In the worst case every time the body of the if is executed, but it takes constant time and so does the code outside of the loop. Thus the running time is .
1.1、快速排序的性能:
快速排序的运行时间依赖于划分是否平衡,而平衡与否又依赖于划分的元素。如果划分是平衡的,那么快排性能与归并排序一样。如果划分不平衡,快排性能接近于插入排序。
最坏情况划分:当产生的两个子问题分别包含了n-1个元素和0个元素时。不妨假设算法的每一次递归调用中都出现了这种不平衡划分,划分操作的时间复杂度是。由于对一个大小为0的数组进行递归调用会直接返回,因此 。
。
可以写出运行时间的递归式:

代入法:直观上,每一层的代价都会被累加起来,从而我们将表示为 ,
,

也就是说,在算法的每一层递归上,划分都是最大程度不平衡的。在最坏情况下,快排运行时间并不比插入排序更好,此外,输入数组已经完全有序时,快排的时间复杂度仍旧是 。但是在同样情况下,插入排序的时间复杂度为
。但是在同样情况下,插入排序的时间复杂度为 。
。
最好情况划分:最平衡的划分时,PARTION得到的两个子问题的规模都不大于 。这是因为其中一个子问题的规模为
。这是因为其中一个子问题的规模为 ,而另一个子问题的规模为
,而另一个子问题的规模为 。
。
运行时间的递归式:

根据主定理,上述递归式的解为 。
。
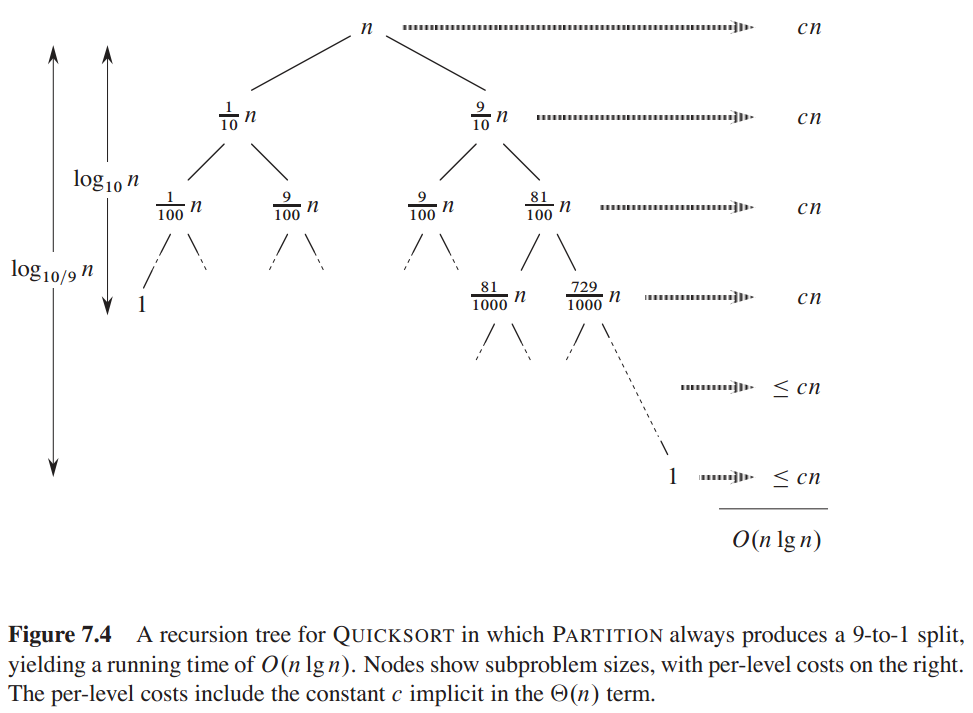
平衡的划分:任何一种常数比例的划分都会产生深度为 的递归树,其中每一层的时间代价为。因此只要划分是常数比例的,算法的运行时间总是
的递归树,其中每一层的时间代价为。因此只要划分是常数比例的,算法的运行时间总是
相关问题:
1)当数组A的所有元素都具有相同值时,QUICKSORT的算法复杂度是多少?
 。因为总有一个划分的子数组有0个元素。
。因为总有一个划分的子数组有0个元素。
2)证:当数组A包含的元素不同,并且是按降序排列的时候,QUICKSORT的算法复杂度是。
这种情况下每次PARTION都会返回p,因为所有元素都大于主元。所以会有一个空的划分。运行时间的递归式如下:
 ,所以
,所以
1.2、快速排序的随机化版本
前面讨论快速排序的平均情况性能时,前提假设:输入数据的所有排列都是等概率的。但是这个假设并不成立。
举个例子:银行一般会按照交易时间来记录某一账户的交易情况。但是,很多人却喜欢收到的银行对账单是按照支票号码的顺序来排列的。人们 通常按照支票号码的顺序来开出支票,而商人也通常都是根据支票编号的顺序对付支票。那么,就是将按交易时间排序的序列转换成按支票号排序的序列。它实质上是一个对几乎有序的输入序列进行排序。在这个问题上,INSERTION-SORT的性能往往要优于QUICKSORT。
通过在算法中引入随机性,使得算法对于所有的输入都能获得较好的期望性能。将随机化版本的快速排序作为大数据输入情况下的排序算法。
采用随机抽样(random sampling)的随机化技术,与始终采用A[r]作为主元的方法不同,随机抽样是从子数组A[p,...,r]中随机选择一个元素作为主元。首先将A[r]与A[p,...,r]中随机选出的一个元素交换。通过对序列p,...,r的随机抽样,可以保证主元元素![x=A[r]](http://ramsey16.net/wp-content/plugins/latex/cache/tex_51861579560a067118b10a1a052b037d.gif) 是等概率地从子数组的r-p+1个元素中选取的。因为主元元素是随机选取的,期望在平均情况下对输入数组的划分是比较均衡的。
是等概率地从子数组的r-p+1个元素中选取的。因为主元元素是随机选取的,期望在平均情况下对输入数组的划分是比较均衡的。

Randomly selecting the pivot element will, on average, cause the split of the input array to be reasonably well balanced.
Randomization of quicksort stops any specific type of array from causing worstcase behavior. For example, an already-sorted array causes worst-case behavior in non-randomized QUICKSORT, but not in RANDOMIZED-QUICKSORT.
使用随机化版本的快速排序期望运行时间为 。
。
相关问题:在RANDOMIZED-QUICKSORT的运行过程中,在最坏情况下,随机数生成器RANDOM被调用了多少次?在最好情况下呢?
最坏情况下, 调用 RANDOM的次数为:
最好情况下:
参考资料:
1)http://www.cnblogs.com/Anker/archive/2013/03/04/2943498.html#3236684
2)http://clrs.skanev.com/07/04/05.html
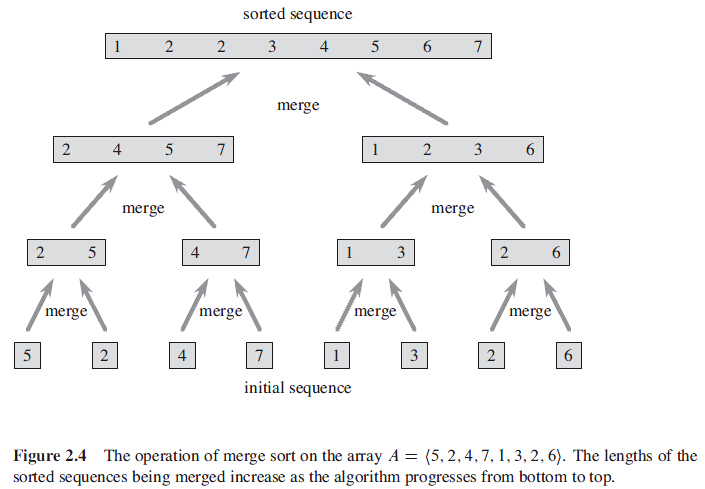
二、归并排序
分解:分解待排序的n个元素的序列成各具n/2个元素的两个子序列
解决:使用归并排序递归地排序两个子序列
合并:合并两个已排序的子序列以产生以排序的答案。
当待排序的序列长度为1时,递归开始回升。长度为1的每个序列都已排好序。
伪代码:
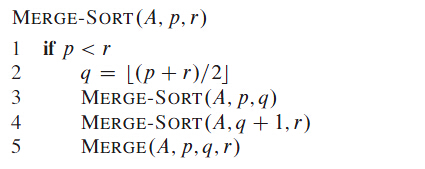
合并两个已经排序的表,取两个输入数组A和B,一个输出数组C以及3 个计数器(Actr、Bctr、Cctr)。





合并两个已经排序的表的时间显然是线性的,因为最多进行了N-1次比较,其中N是元素的总数。每次比较都是添加1个元素到C中,最后一次比较除外,它至少添加两个元素。欲将8个元素的数组24,13,26,1,2,27,38,15排序,递归的将前4个数据和后4个数据分别排序,得到1,13,24,26,2,15,27,38。然后,再将这两部分合并。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
#include <vector> using namespace std; //合并,开辟一个临时数组,merge在mergeSort的最后一行,因此在任一时刻只需要一个临时数组活动, //这个临时数组可以在驱动程序中建立 template<typename T>void Merge(vector<T>&a,vector<T>&tempArray,int leftPos,int rightPos,int rightEnd){ int leftEnd=rightPos-1; int tempPos=leftPos; int numElements=rightEnd-leftPos+1; while(leftPos<=leftEnd&&rightPos<=rightEnd){ if(a[leftPos]<=a[rightPos]) tempArray[tempPos++]=a[leftPos++]; else tempArray[tempPos++]=a[rightPos++]; } while(leftPos<=leftEnd) tempArray[tempPos++]=a[leftPos++];//Copy rest of left half while(rightPos<=rightEnd) tempArray[tempPos++]=a[rightPos++]; for(int i=0;i<numElements;i++,rightEnd--) a[rightEnd]=tempArray[rightEnd]; } template<typename T>void MergeSort(vector<T>&a,vector<T>&tempArray,int left,int right){ if(left<right){ int center=(left+right)/2; MergeSort(a,tempArray,left,center); MergeSort(a,tempArray,center+1,right); Merge(a,tempArray,left,center+1,right); } } template <typename T>void MergeSort(vector<T>&a){ vector<T>tempArray(a.size()); MergeSort(a,tempArray,0,a.size()-1); } int _tmain(int argc, _TCHAR* argv[]) { vector<int> a; a.push_back(24); a.push_back(13); a.push_back(26); a.push_back(1); a.push_back(2); a.push_back(27); a.push_back(38); a.push_back(15); MergeSort(a); return 0; } |
递归调用过程:24、13;然后26、1;然后2、27;然后38、15。接着24、13、26、1;然后2、27、38、15。
T(1)=1
T(N)=2T(N/2)+N
可以推得T(N)=NlogN+N=O(NlogN)。
非递归迭代实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
// 将原数组划分为left[min...max] 和 right[min...max]两部分 template<typename T>void NonIter_MergeSort(vector<T>&a){ int length=a.size(); vector<T>tempArray(a.size()); int i, left_min, left_max, right_min, right_max, next; // i为步长,1,2,4,8…… for (i = 1; i < length; i *= 2){ //leftmin=rightmax,就是每一次实现步长操作 for (left_min = 0; left_min < length - i; left_min = right_max){ right_min=left_max=left_min+i;// right_max = left_max + i; if (right_max > length) right_max=length; next = 0; while (left_min < left_max && right_min < right_max){ tempArray[next++] = a[left_min] > a[right_min] ? a[right_min++] : a[left_min++]; } while(left_min<left_max) a[--right_min] = a[--left_max]; while (next > 0) a[--right_min] = tempArray[--next]; } } } |
虽然归并排序的运行时间是O(NlogN),但它很难用于主存排序。因为合并两个排序的表需要线性附加内存,还要花费将数据复制到临时数组再复制回来的一些附加工作。严重减慢了排序的速度。归并排序的运行时间很大程度上依赖在数组中进行元素的比较和移动所消耗的时间,这些消耗是和编程语言相关的。
JAVA中,当排序一般的对象时,元素的比较耗时很多,但是移动元素就快得多,在所有流行的排序算法中,归并排序使用最少次数的比较。所以,在JAVA中,归并排序是标准JAVA库中的实现。
参考资料:
1)《算法导论》第3版 第7章,第2章
2)http://clrs.skanev.com/
3)http://www.zhihu.com/question/19817683