数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class BinarySearchTreeNode { public: struct BinarySearchTreeNode *left; struct BinarySearchTreeNode *right; struct BinarySearchTreeNode *parent; int key; }; //typedef struct BinarySearchTreeNode BinarySearchTreeNode; class BinarySearchTree{ public: BinarySearchTree(); void tree_insert(const int &key); int tree_remove(const int &key); BinarySearchTreeNode *tree_search(const int &elem)const; int tree_minmum(BinarySearchTreeNode *root)const; int tree_maxmum(BinarySearchTreeNode *root)const; int tree_successor(const int&key)const; int tree_predecessor(const int&key)const; void inorder_tree_walk()const; void tree_print(BinarySearchTreeNode *root)const; int empty()const; private: BinarySearchTreeNode* root; }; |
|
1 2 3 4 5 6 7 |
BinarySearchTree::BinarySearchTree(){ root = NULL; } int BinarySearchTree::empty()const{ return (root == NULL); } |
查找
在一棵二叉搜索树种查找一个具有给定关键字的结点。输入一个指向树根的指针和一个关键字k,如果这个结点存在,TREE-SEARCH返回一个指向关键字为k的结点的指针;否则返回NULL。

伪代码
|
1 2 3 4 5 6 7 |
ITERATIVE-TREE-SEARCH(x,k) 1 while x!=NULL and k!=x.key 2 if k<x.key 3 x=x.left 4 else 5 x=x.right 6 return x |
对于大多数计算机,迭代版本的效率要高得多。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BinarySearchTreeNode *BinarySearchTree::tree_search(const int &elem)const{ BinarySearchTreeNode *pnode = root; while (pnode){ if (pnode->key == elem) //这里千万注意,别写成=!!惨痛教训 break; else if (pnode->key > elem) pnode = pnode->left; else pnode = pnode->right; } return pnode; } |
最大关键字元素和最小关键字元素
我们知道,由于二叉搜索树的性质,我们很容易就可以去找出树中的最小元素和最大元素,这两个过程在一棵高度为h的树上均能在O(h)时间内完成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int BinarySearchTree::tree_minmum(BinarySearchTreeNode *root)const{ BinarySearchTreeNode *pnode = root; if (pnode->left){ while (pnode->left) pnode = pnode->left; } return pnode->key; } int BinarySearchTree::tree_maxmum(BinarySearchTreeNode *root)const{ BinarySearchTreeNode *pnode = root; if (pnode->right){ while (pnode->right) pnode = pnode->right; } return pnode->key; } |
后继和前驱(SUCCESSOR,PREDECESSOR)
给定一个二叉查找树中的结点,找出在中序遍历顺序下某个节点的前驱和后继。如果树中所有关键字都不相同,则某一结点x的前驱就是小于x.key的所有关键字中最大的那个结点,后继即是大于x.key中的所有关键字中最小的那个结点。一棵二叉搜索树的结构允许我们通过没有任何关键字的比较来确定一个结点的后继。
查找前驱:先判断x是否有左子树,如果有则在left[x]中查找关键字最大的结点,即是x的前驱。如果没有左子树,则从x继续向上执行此操作,直到遇到某个结点是其父节点的右孩子结点。例如下图查找结点7的前驱结点6过程:

伪代码
|
1 2 3 4 5 6 7 8 |
TREE-PREDECESSOR(x) 1 if x.left!=NULL 2 return TREE-MAXIMUM(x.left) 3 y=x.parent 4 while(y!=NULL and x==y.left) 5 x=y 6 y=y.parent 6 return y |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
int BinarySearchTree::tree_predecessor(const int&key)const{ BinarySearchTreeNode *pnode = tree_search(key); BinarySearchTreeNode *parentnode; if (pnode != NULL){ if (pnode->left) return tree_maxmum(pnode->left); parentnode = pnode->parent; while (parentnode != NULL &&pnode == parentnode->left){ pnode = parentnode; parentnode = pnode->parent; } if (parentnode != NULL) return parentnode->key; else return 0; } return 0; } |
查找后继步骤:先判断x是否有右子树,如果有则在x.right中查找关键字最小的结点,即为x的后继。如果没有右子树,则从x的父节点开始向上查找,直到遇到某个结点是其父结点的左儿子的结点时为止。例如下图查找结点13的后继结点15的过程。

伪代码
|
1 2 3 4 5 6 7 8 |
TREE-SUCCESSOR(x) 1 if x.right!=NULL 2 return TREE-MINIMUM(x.right) 3 y=x.parent 4 while(y!=NULL and x==y.right) 5 x=y 6 y=y.parent 6 return y |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
int BinarySearchTree::tree_predecessor(const int&key)const{ BinarySearchTreeNode *pnode = tree_search(key); BinarySearchTreeNode *parentnode; if (pnode != NULL){ if (pnode->left) return tree_maxmum(pnode->left); parentnode = pnode->parent; while (parentnode != NULL &&pnode == parentnode->left){ pnode = parentnode; parentnode = pnode->parent; } if (parentnode != NULL) return parentnode->key; else return 0; } return 0; } |
插入和删除
插入和删除会引起二叉查找表示的动态集合的变化,难点在在插入和删除的过程中要保持二叉查找树的性质。
要将一个新值key插入到一棵二叉搜索树T中,需要调用过程TREE-INSERT。以结点z作为输入(newnode),其中z.key=key,z.left=NULL,z.right=NULL。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
TREE_INSERT(T,z) y = NULL; x =T.root while x != NULL y =x if z.key <x.key x=x.left else x=x.right z.parent=y if y==NULL T.root =z //tree T was empty else if z.key<y.key y.left = z else y.right =z |
算法复杂度:
显然,在一棵高度为h的树上的运行时间为O(h)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
void BinarySearchTree::tree_insert(const int&key){ if (!empty()){ BinarySearchTreeNode *pnode = root; //x=T.root BinarySearchTreeNode *qnode = NULL; //y 作为遍历指针,作为x的parent BinarySearchTreeNode *newnode = new BinarySearchTreeNode(); newnode->key = key; newnode->parent = NULL; newnode->left = NULL; newnode->right = NULL; while (pnode){ //while(x!=NULL) qnode = pnode; //y=x,这里y其实就是作为x的parent z.p=y if (pnode->key > key) pnode = pnode->left; else pnode = pnode->right; } if (qnode->key > key) qnode->left = newnode; else qnode->right = newnode; newnode->parent = qnode; } else{ root = new BinarySearchTreeNode(); root->key = key; root->parent = NULL; root->left = NULL; root->right = NULL; } } |
中序遍历
这就是12.1-3中执行中序遍历的非递归算法。使用栈作为辅助数据结构
12.1-3 给出一个非递归的中序树遍历算法。(提示:有两种方法,在较容易的方法中,可以采用栈作为辅助数据结构;较复杂的方法中,不采用栈结构,但假设可以测试两个指针是否相等)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
void BinarySearchTree::inorder_tree_walk()const{ if (!empty()){ stack<BinarySearchTreeNode*> mystack; BinarySearchTreeNode *ptempnode; ptempnode = root; while (ptempnode != NULL|| !mystack.empty()){ if (ptempnode != NULL){ mystack.push(ptempnode);//将左子树的结点分别压栈,直到到达叶结点 ptempnode = ptempnode->left; } else{ ptempnode = mystack.top();//出栈 mystack.pop(); cout << ptempnode->key << " "; ptempnode = ptempnode->right; //如果其有右孩子,那么压栈;如果没有,则继续出栈左孩子 } } } } |
删除
从二叉搜索树中删除一个结点z的整个策略可以分为三种基本情况。
- 如果z没有孩子结点,那么将它删除,并修改它的父结点,用NULL作为孩子来替换z。

- 如果结点z只有一个子树(左子树或者右子树),那么将这个孩子提升到树中z的位置上。删除过程如下图所示

- 如果z有两个孩子,那么找z的后继y(一定在z的右子树中),并让y占据树中z的位置。z的原来右子树部分成为y的新的右子树,并且z的左子树成为y的新的左子树。

考虑 图12-4中的四种情况
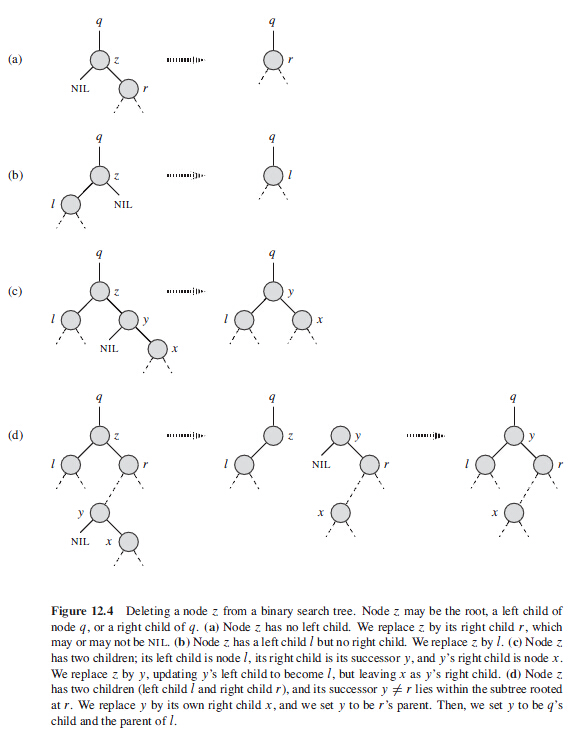
- (a)如果z没有左孩子,那么用其右孩子来代替z。这个右孩子可以是NULL,也可以不是。当z的右孩子是NULL时,这种情况可以归为z没有孩子结点的情况。当右孩子非NULL时,即z仅有一个孩子结点的情形。
- (b)如果z仅有一个孩子且为其左孩子,那么用其左孩子来替换z。
- z既有一个左孩子,又有一个右孩子,查找z的后继y,这个后继位于z的右子树中并且没有左孩子。(这一点需要证明)
- (c)如果y是z的右孩子,那么用y替换z,并仅留下y的右孩子
- (d)否则,y位于z的右子树但并不是z的右孩子,并且z的后继y!=r位于以r为根的子树中。这种情况下,先用y的右孩子替换y,并且置y为r的parent。然后,再置y为q的孩子和r的parent。
子过程TRANSPLANT
用另一棵子树替换一棵子树并成为其双亲的孩子结点。当TRANSPLANT用一棵以v为根的子树来替换一棵以u为根的子树时,结点u的双亲就变为结点v的双亲,并且最后v成为u的双亲的相应孩子。(这段话结合下面程序理解)
|
1 2 3 4 5 6 7 8 |
TRANSPLANT(T,u,v) 1 if u.p==NULL 2 T.root=v; 3 elseif u=u.parent.left 4 u.parent.left=v 5 else u.parent.right=v 6 if v!=NULL 7 v.parent=u.parent |
明天继续红黑树及AVL树
参考资料:
1)http://www.cnblogs.com/Anker/archive/2013/01/28/2880581.html
2)