Ensemble Learning
对于一个分类器,分类误差和两个指标有关系:bias,分类器的准确率(在训练样本上的误差);variance,分类器的预测精度,即泛化能力。两个指标之间有一个trade-off:低偏倚的分类器往往具有较高的方差;而高偏倚的分类器具有较低的方差。平均化(averaging)具有平滑(减少方差)的作用。所以集成学习的目标是学习一组具有相似(接近固定)的偏倚的分类器,通过组合其输出并平均化来较少方差。
 variability的减小可以认为是通过一个平均滤波器来减小高频噪声(对应于高方差),每个样本的信号由其邻域内的样本求取平均。这里有一个问题,PCA中认为高方差是有效的信号,那么这里所指方差与PCA协方差矩阵的方差是否为一个概念呢?
variability的减小可以认为是通过一个平均滤波器来减小高频噪声(对应于高方差),每个样本的信号由其邻域内的样本求取平均。这里有一个问题,PCA中认为高方差是有效的信号,那么这里所指方差与PCA协方差矩阵的方差是否为一个概念呢?
在集成学习的框架下,1)如何组合各个分类器有很多方法,求取输出平均只是其中一种(对应于后文会讲到的bagging思想)。2)组合分类器的输出并不能保证分类性能一定好于所有分类器中(ensemble)中最好的分类器。其实,只是减小了选择一种弱分类器的似然可能。如果存在先验知识可知哪个分类器分类性能最佳,那么就只要选择这个分类器而不必要进行集成学习。
集成学习的方法有:bagging [6], random forests (an ensemble of decision trees), composite classifier systems [1], mixture of experts (MoE) [7, 8], stacked generalization [9], consensus aggregation [10],combination of multiple classifiers [11–15], dynamic classifier selection [15],classifier fusion [16–18], committee of neural networks [19], classifier ensembles[19, 20], among many others.
可分为:classifier selection和clssifier fusion.后者所有分类器都在整个特征空间进行训练,并组合得到一个较低方差(较低错误)的分类器。
一个集成学习的系统主要分为三个部分:
- 数据采样/选择(data sampling/selection)
- 训练成员分类器(training member classifier)
- 组合分类器(combining classifiers)
1)理想情况下,各个分类器的输出应该是独立的或者负相关(negatively correlated)。(显然, 如果每个子分类器输出相同,那么就无法从组合中获得有效信息)。最常见的做法是如上图所示使用训练数据的不同子集来训练各个分类器以获得整个集合的多样性(diversity)。
另外,使用bootstrap重复抽样后的训练样本复本会产生bagging方法,而对于错分类样本的关注则是boosting算法的核心;使用特征的不同子集来训练每个分类器称为random subspace methods[34];采用基分类器的不同参数(如训练多层感知机的ensemble,每一层有不同数目的隐层节点)。
2)组合分类器。对于某些分类器如SVM,只提供离散值的标号输出。另外一些分类器,如多层感知器及朴素贝叶斯分类器,提供连续输出值,即可解释为对应于每一类的支持机。
2.1)组合类标号。假定分类器输出为类标号,第 个分类器的决策为
个分类器的决策为 ,
, ,
, 。
。 为分类器数目,
为分类器数目, 为类别数目。如果
为类别数目。如果 个分类器
个分类器 选择类
选择类 ,那么相应的
,那么相应的 。从而连续输出值可以转换为标好输出。
。从而连续输出值可以转换为标好输出。
多数投票(Majority Voting):
Boosting思想
Kearns和Valiant提出“强可学习”和“弱可学习”的概念:在概率近似正确(probably approximately correct,PAC)学习的框架中,一个概念(类), 如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅仅比随机猜测略好,那么称这个概念是弱可学习的。Schapire证明:在PAC学习的框架下,一个概念时强可学习的充分必要条件是一个概念是弱可学习的。
也就是说,如果已经发现“弱可学习算法”,能否将它提升(boosting)为“强可学习算法”。大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布用弱学习算法学习一系列弱分类器。
Adaboost(adaptive boosting)是一种可以用于分类或者回归的集成学习方法(ensemble learning)。尽管Adaboost相对于其他机器学习方法不易过拟合(能否从satistical view来解释?),它对于噪声数据和异常值较为敏感。
Adaboost之所以称为adaptive是因为它用了许多次迭代来生成一个强分类器。
Adaboost能得到的结论是不断增加弱分类器,训练误差的上界会不断下降。
AdaBoostM1(对于二分类问题)
对于每一个学习分类分类器,AdaBoostM1 计算权重分类误差(weighted classification error)。
1)构建X为样本集,Y为样本类别标识集,假设限定Y={-1,+1},则可构建训练样本集
2)初始化m个样本的权重,假设样本分布 为均匀分布:
为均匀分布: ,
, 表示在第轮迭代中赋给样本
表示在第轮迭代中赋给样本 的权值。
的权值。
3)For t=1 to T
根据样本分布,通过对训练集S进行抽样(有放回的)产生训练集 。在训练集上训练分类器,再用分类器对原训练集S中所有样本进行分类,可得到本轮分类器的权重误差:
。在训练集上训练分类器,再用分类器对原训练集S中所有样本进行分类,可得到本轮分类器的权重误差:

where
 is a vector of predictor values for observation i;
is a vector of predictor values for observation i;  is the true class label; ht is the prediction of learner (hypothesis) with index t;
is the true class label; ht is the prediction of learner (hypothesis) with index t;  is the indicator function; is the weight of observation i at step t.
is the indicator function; is the weight of observation i at step t.
AdaBoostM1算法增大对于被分类器错分的样本权重,然后减小对于被分类器正确分类的样本权重。在更新权重的样本后,训练得到下一个分类器 .
.
更新每个训练样本的权重:

其中, 是一个正规因子,以确保
是一个正规因子,以确保
![\alpha_{t}=\frac{1}{2}(ln[\frac{\epsilon_{t}}{1-\epsilon_{t}}])](http://ramsey16.net/wp-content/plugins/latex/cache/tex_a6e2fed0b6a233ab2a81d24157093a5f.gif)
4)最终的强分类器为:

Adaboost的训练可以看做对指数损失 的stagewise minimization。
的stagewise minimization。
where  is 归一化到(0-1)的样本权重,是一开始设定的权重; is the true class label;
is 归一化到(0-1)的样本权重,是一开始设定的权重; is the true class label;  为预测分类分数。
为预测分类分数。
The second output from the predict method of an AdaBoostM1 classification ensemble is an N-by-2 matrix of classification scores for the two classes and Nobservations. The second column in this matrix is always equal to minus the first column. predict returns two scores to be consistent with multiclass models, though this is redundant because the second column is always the negative of the first.
大多数情况下,AdaBoostM1默认使用decision stumps或者shallow trees。如果boosted stumps不能获得比较好的效果,可以尝试减少父母节点的数量为训练数据的四分之一。
同时,boosting算法默认的学习率为1。如果减小学习率,boosting算法会以更慢的速度收敛到一个更优的解。一般可以设为0.1。以小于1的学习率通常称为“收缩”(shrinkage)
讨论:
Adaboost的魂在于其样本权重更新(样本权重模拟了概率分布)和弱分类器加权组合。其样本权重更新保证了前面的弱分类器重点处理普遍情况,而后续的分类器重点处理疑难杂症,最终,弱分类器加权组合保证了前面的普遍情况弱分类器会有更大的权重。这其实有先抓总体,再抓特例的分而治之的思想
adaboost不会过拟合这是个伪命题,肯定是无法证明的。而“adaboost不易过拟合”,这似乎又是一个无法证伪也无法证明的问题,因为这不是一个严谨的结论,无法证明。而adaboost的各种版本中,我知道的泛化能力最好的应该是gentle adaboost,因为其权重更新过程比较gentle,直观理解gentle的求优过程,自然会使得泛化更好。
附录:
Matlab工具包介绍
|
1 |
ens = fitensemble(X,Y,model,numberens,learners) |
Xis the matrix of data. Each row contains one observation, and each column contains one predictor variable.Yis the vector of responses, with the same number of observations as the rows inX.modelis a string naming the type of ensemble.numberensis the number of weak learners inensfrom each element oflearners. So the number of elements inensisnumberenstimes the number of elements inlearners.learnersis either a string naming a weak learner, a weak learner template, or a cell array of such templates.

Choose an Applicable Ensemble Method
fitensemble uses one of these algorithms to create an ensemble.
- For classification with two classes:
'AdaBoostM1''LogitBoost''GentleBoost''RobustBoost'(requires an Optimization Toolbox™ license)'LPBoost'(requires an Optimization Toolbox license)'TotalBoost'(requires an Optimization Toolbox license)'RUSBoost''Subspace''Bag'
- For classification with three or more classes:
'AdaBoostM2''LPBoost'(requires an Optimization Toolbox license)'TotalBoost'(requires an Optimization Toolbox license)'RUSBoost''Subspace''Bag'
- For regression:
'LSBoost''Bag'
This table lists characteristics of the various algorithms. In the table titles:
Regress.— RegressionClassif.— ClassificationPreds.— Predictors-
Imbalance— Good for imbalanced data (one class has many more observations than the other) Stop— Algorithm self-terminatesSparse— Requires fewer weak learners than other ensemble algorithms
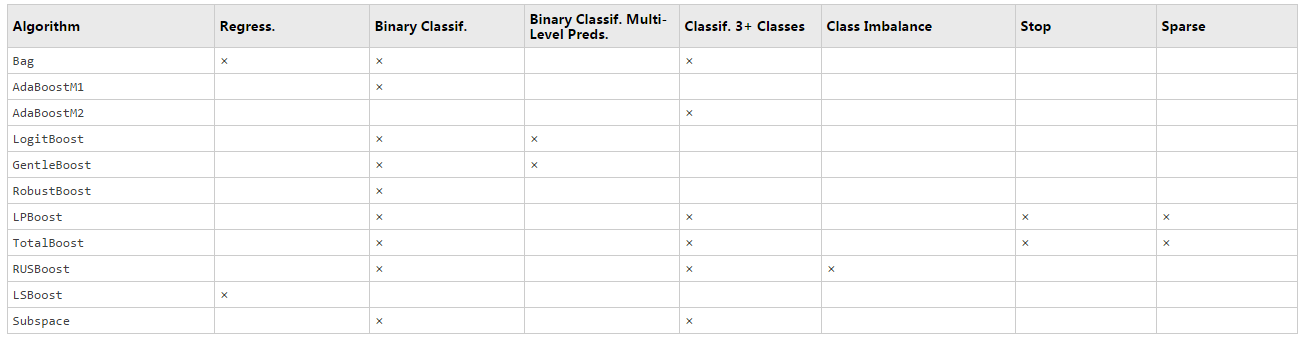
应用实例:
Fisher's Iris data set,是一类多重变量分析的数据集。
其数据集包含了50个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。
参考资料:
1) Freund and Schapire [16],
2)Schapire et al. [26],
3)Friedman, Hastie, and Tibshirani [18], and Friedman [17].
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/02/machine-learning-boosting-and-gradient-boosting.html
http://blog.csdn.net/sunmenggmail/article/details/8956986
http://www.zhizhihu.com/html/y2011/3327.html
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/1976562.html
http://wenku.baidu.com/link?url=DEd5eTO1oHhGf__m99Ed7I3mPnNhWDokrg0E2b5LNfsnAOr29TA_byO2Nr2DduzfJdtOUQy5PbeITATgB935OQa8p-F5u-aHBuOg8jxlX5i
http://blog.csdn.net/dark_scope/article/details/24863289
next permutation
http://blog.csdn.net/qq575787460/article/details/41206601