后缀树
后缀:后缀是指从某个位置i 开始到整个串末尾结束的一个特殊子串。字符串r 的从第i 个字符开始的后缀表示为Suffix(i) ,也就是
![Suffix(i)=r[i,..., len(r)]](http://ramsey16.net/wp-content/plugins/latex/cache/tex_c9fe1cbd0c2abf5069517cb31d310773.gif) 。
。
一棵后缀树包含了一个或者多个字符串的所有后缀。空字符串也算其中一个后缀。对于字符串banana,其所有后缀为:banana anana nana ana na a 空。通常为了更清楚地表示出后缀,我们在字符串末尾添加一个特殊字符作为结束标记,在这里我们使用$。因此banana的所有后缀就可以表示为: banana$ anana$ nana$ ana$ na$ a$ $
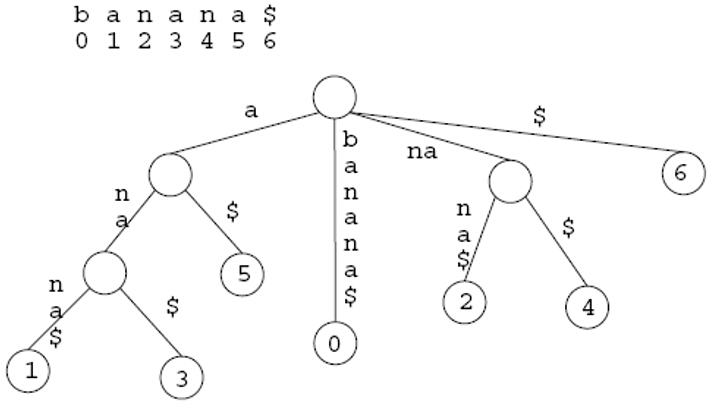
后缀树与TRIE
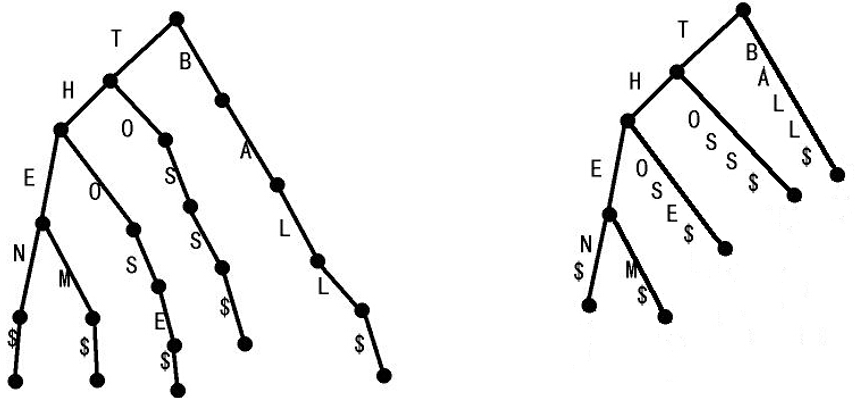
事实上,后缀树就是一个压缩后的Trie,存储了字符串所有的后缀。对Trie进行压缩,对只有一个儿子的节点进行合并。
后缀树的应用(注意,这里都是后缀)
1)查找一个字符串S是否包含了字串T:
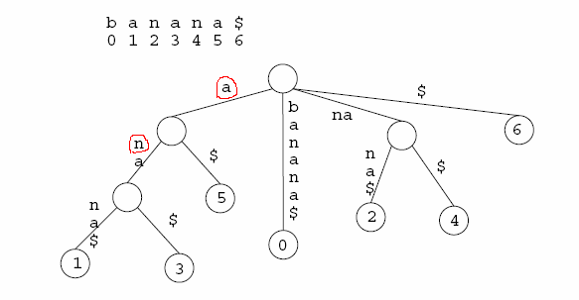
如果S包含T,那么T必定是S的某个后缀的前缀。因为S的后缀树包含了所有的后缀,因此只需对S的后缀树使用和Trie相同的查找方法即可。
举例:在banana中查找an
2)统计S中出现T的次数:
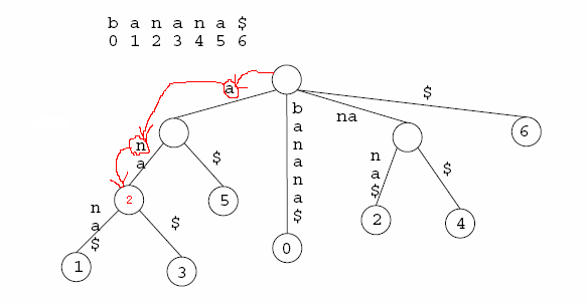
每出现一次T,必定对应着一个不同的后缀,而这所有的后缀又都有着共同的前缀T。因此这些后缀在S的后缀树中必定属于某一棵子树。这棵子树的叶子数便等于T在S中出现的次数。
举例:统计banana中出现an的次数
3)找出S中最长的重复子串。所谓重复子串是指出现了两次以上的子串。
首先定义节点的“字符深度”=从后缀树根节点到每个节点所经过的字符串总长。找出有最大字符深度的非叶节点,则从根节点到该非叶节点所经过的字符串即为所求。
举例:banana的最长重复子串为ana

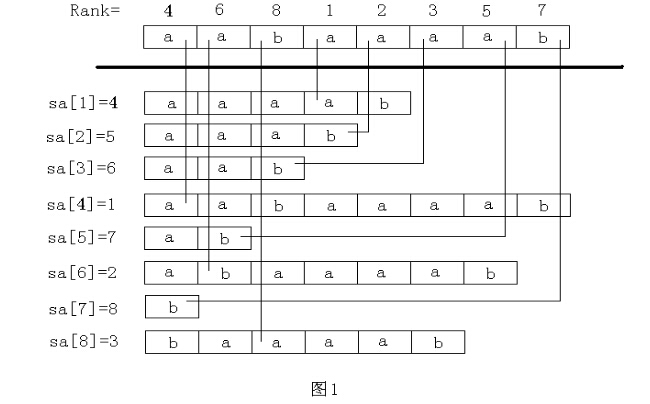
后缀数组
后缀数组:后缀数组SA 是一个一维数组,它保存1..n 的某个排列SA[1],SA[2],……,SA[n],并且保证Suffix(SA[i]) < Suffix(SA[i+1]),1≤i<n。
也就是将S 的n 个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入SA 中。
名次数组:名次数组Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的“名次”。(从第i个字符串开始排序)
公共子串:如果字符串L同时出现在字符串A和字符串B中,则称字符串L是字符串A和字符串B的公共子串。
分析:字符串的任何一个子串都是这个字符串的某个后缀的前缀。求A和B的最长公共子串等价于求A的后缀和B的后缀的最长公共前缀的最大值。如果枚举A和B的所有的后缀,那么这样做显然效率低下。由于要计算A的后缀和B的后缀的最长公共前缀,所以先将第二个字符串写在第一个字符串后面,中间用一个没有出现过的字符隔开,再求这个新的字符串的后缀数组。观察一下,看看能不能从这个新的字符串的后缀数组中找到一些规律。以A=“aaaba”,B=“abaa”为例,如图8所示。
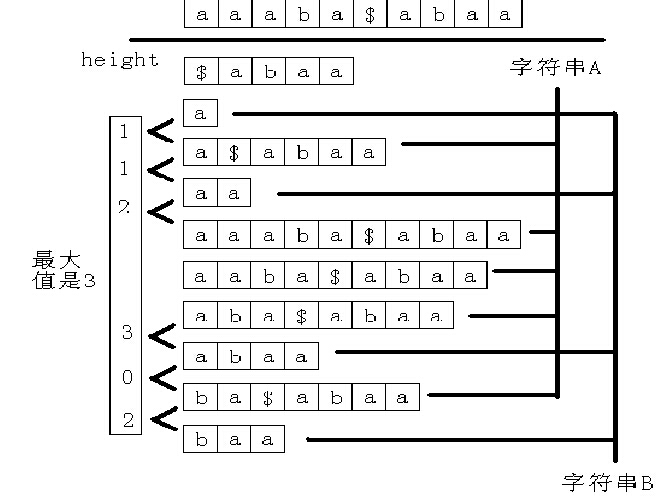
记字符串A 和字符串B 的长度分别为|A|和|B|。求新的字符串的后缀数组和height 数组的时间是O(|A|+|B|),然后求排名相邻但原来不在同一个字符串中的两个后缀的height 值的最大值, 时间也是O(|A|+|B|),所以整个做法的时间复杂度为O(|A|+|B|)。
1、给定一个 query 和一个 text,均由小写字母组成。要求在 text 中找出以同样的顺序连 续出现在 query 中的最长连续字母序列的长度。例如, query 为“acbac”,text 为 “acaccbabb”,那么 text 中的“cba”为最长的连续出现在 query 中的字母序列,因此, 返回结果应该为其长度 3。请注意程序效率。(阿里巴巴)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
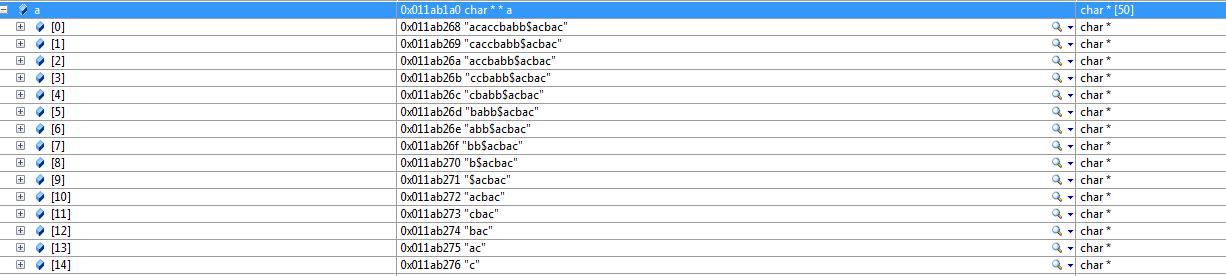
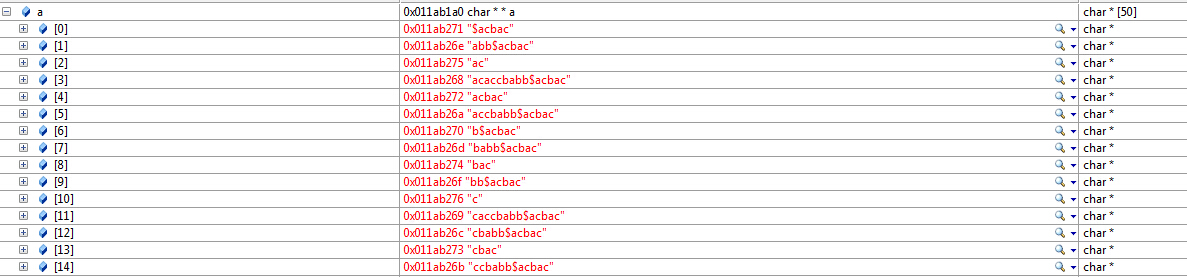
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <cstdlib> #include <cstring> #include <iostream> using namespace std; #define MAXN 500000 char c[MAXN], *a[MAXN]; //要对a这个数组进行排序,而这个数组里面的内容均是指针,回想一下qsort对普通数组的用法, //qsort的第四个参数比较函数对传入的函数均要求是指针,所以,在这里,pstrmcp传入的是a这个数组每个元素的指针, //所以指向指针的指针,这也就是为什么在进行强制类型转换时是char **的原因了 int pstrcmp(const void *x,const void *y) { return strcmp(*(char **)x,*(char **)y); } int commonlen(char *p,char *q)//统计相邻单词共有的字符数 { int i=0; while(*p && (*p++==*q++)) { i++; } return i; } int strl(const char *s){ int i,k=0; for(i=0;s[i];i++)k++; //finde s[i]=’\0’ return k; } //_CRTIMP void __cdecl qsort(_Inout_bytecap_x_(_NumOfElements * _SizeOfElements) void * _Base, // _In_ size_t _NumOfElements, _In_ size_t _SizeOfElements, // _In_ int (__cdecl * _PtFuncCompare)(const void *, const void *)); int _tmain(int argc, _TCHAR* argv[]) { int maxlen=-1; int maxindex; string word="acaccbabb"; string query="acbac"; const char *word1 = word.c_str(); const char *query1 = query.c_str(); int len1=strl(word1); int len2=strl(query1); int n; for(n=0;n<len1;n++){ c[n]=*(word1+n); a[n]=&c[n]; } c[n]='$'; a[n]=&c[n]; for(n=len1+1;n<len1+len2+1;n++){ c[n]=*(query1+n-len1-1); a[n]=&c[n]; } c[n]='\0'; qsort(a,n,sizeof(char *),pstrcmp); for(int i=0;i<n-1;i++) { if(commonlen(a[i],a[i+1])>maxlen) { maxlen=commonlen(a[i],a[i+1]); maxindex=i; } } return 0; } |
参考资料:
1)罗穗骞, “后缀数组——处理字符串的有力工具” NOI国家集训队
2)百度文库, “后缀树入门”
3)编程珠玑,第15章