首先让我们回顾一下二分类问题的分界面。
令分界面线性函数为 ,
, 称为权重向量,
称为权重向量, 称为偏置(bias)。偏置的负值也称为阈值(threshold)。也就是说,对于一个输入向量
称为偏置(bias)。偏置的负值也称为阈值(threshold)。也就是说,对于一个输入向量 ,如果
,如果 ,那么被分配为类
,那么被分配为类 。否则被分配为类
。否则被分配为类 。
。

如图,如果一个点在分界面 上,那么从原点到该分界面的法向量可以写为
上,那么从原点到该分界面的法向量可以写为 。令
。令 为向量在决策面上的正交投影点到原点的投影向量,那么可以得到
为向量在决策面上的正交投影点到原点的投影向量,那么可以得到

两边同乘 并加上,可以得到
并加上,可以得到

为了编程方便,我们一般增加一个dummy input  ,令
,令 ,
, ,
,
多分类问题
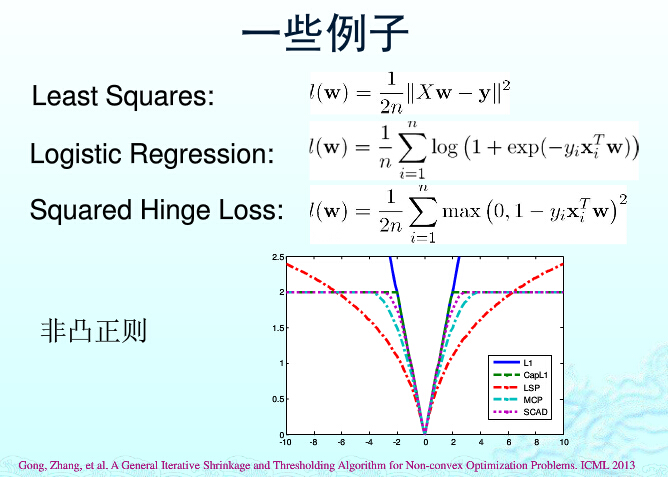
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类:一类是直接法,直接在目 标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;另一类是间接法,主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
- 一对多法(one-versus-rest,简称1-v-r SVMs)。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
- 一对一法(one-versus-one,简称1-v-1 SVMs)。其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计
 个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。这样做的问题其实可以从上图显示,会产生一个ambiguous的区域。
个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。这样做的问题其实可以从上图显示,会产生一个ambiguous的区域。
考虑一个K类的分解面包含K个线性函数, ,将点分配给类
,将点分配给类 ,如果
,如果 对于所有
对于所有 。类与类
。类与类 之间的分界面可以由
之间的分界面可以由 给定,即一个
给定,即一个 维的超平面
维的超平面


对于任一一点类的点,如图 ,有
,有 ,可证
,可证 区域是单连通的且为凸。
区域是单连通的且为凸。
SVM(Maximum Margin Classifier)
SVM的一个很好的性质就是模型参数的确定等同于一个凸优化问题,因此肯定有全局最优解。SVM是一个决策机,不像LR等分类器提供后验概率(posterior probabilities)。

其中, 表示特征映射函数。
表示特征映射函数。
有N组输入向量 ,其相应的输出值为
,其相应的输出值为 ,
, 。
。
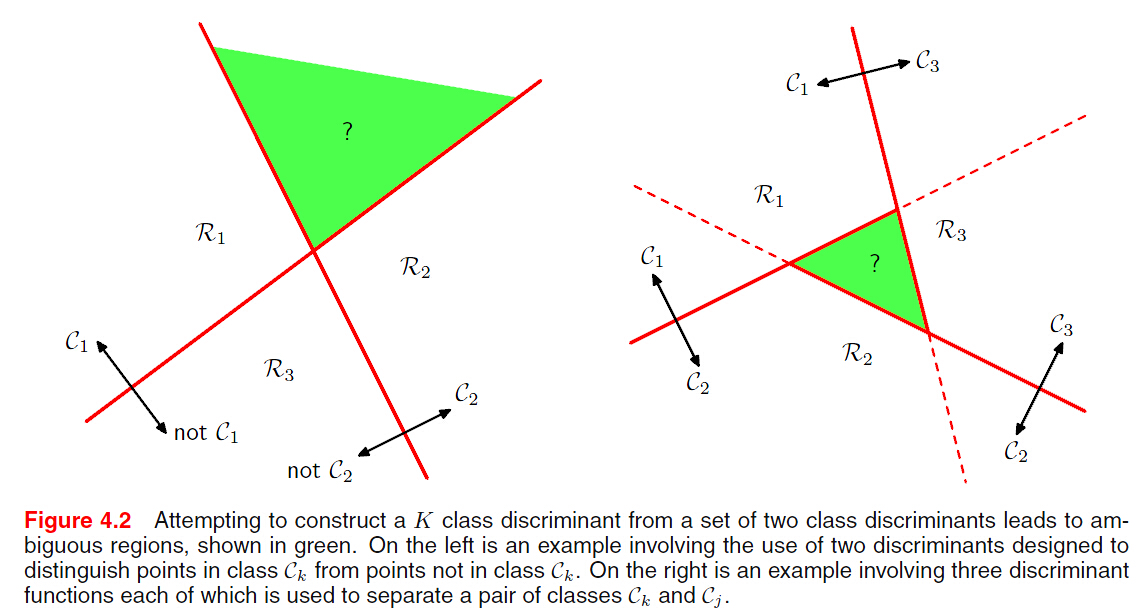
感知机存在的问题:保证在有限步内找到解,但是找到的这个解依赖于(任意)初始值和 ,以及数据点放置的顺序。
,以及数据点放置的顺序。
 这就是所谓的Margin.如果存在多个解能将训练数据正确分类,寻找泛化误差最小(Margin)的解。
这就是所谓的Margin.如果存在多个解能将训练数据正确分类,寻找泛化误差最小(Margin)的解。

其中,我们注意到一个现象,令 ,
, ,
, 值不变。
值不变。
Maximum Margin Solution
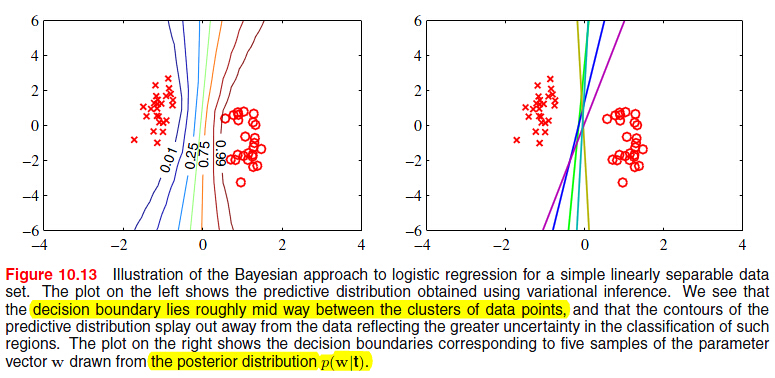
(marginalization with respect to the prior distribution of the parameters in a Bayesian approach for a simple linearly separable dataset leads to a decision boundary that lies in the middle of the region separating the
data points. The large margin solution has similar behaviour.)
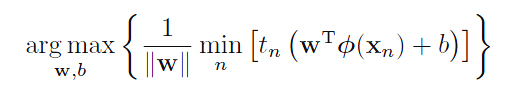
其中, 与
与 无关。
无关。
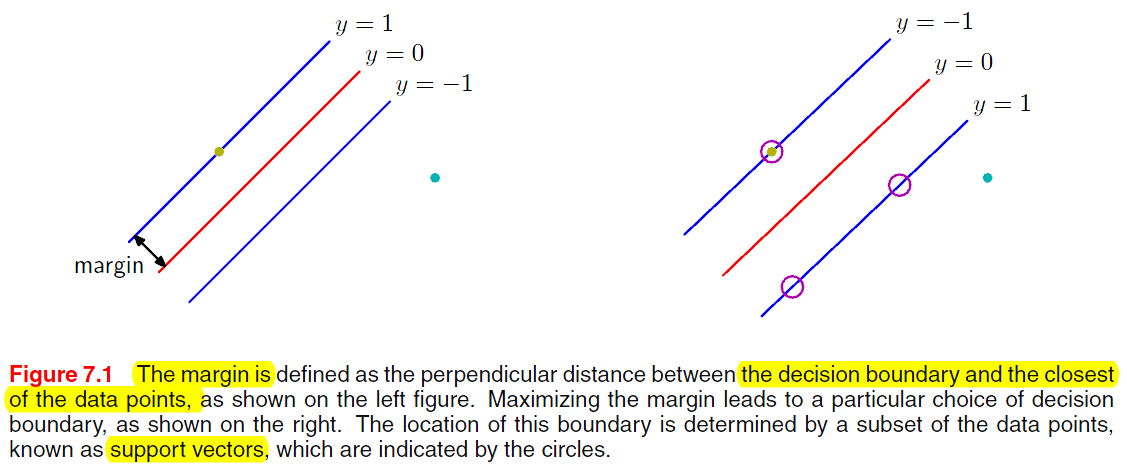
我们令 为距离surface最近的点,那么所有的数据点都应该满足
为距离surface最近的点,那么所有的数据点都应该满足 。当等号成立时,约束 ative;不成立时,约束Inactive。
。当等号成立时,约束 ative;不成立时,约束Inactive。
优化问题简化为求解
 subject to ,
subject to ,
等同于
 subject to ,
subject to ,
引入其拉格朗日形式
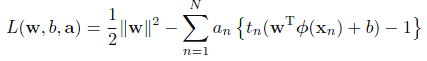
其中 。注意拉格朗日乘子项前的符号,因为我们是对和最小化,而对
。注意拉格朗日乘子项前的符号,因为我们是对和最小化,而对 做最大化。令目标函数对和求偏导并令其为0。
做最大化。令目标函数对和求偏导并令其为0。

代入上式消去和,可以得到该问题的对偶形式(dual representation)。

其中![]() 。(这个性质非常好!!!参见内积:相似性的度量一文)。
。(这个性质非常好!!!参见内积:相似性的度量一文)。

有M个变量的二次规划问题(quadratic programming)时间复杂度为 。对偶问题只有N个变量,对于基函数的个数
。对偶问题只有N个变量,对于基函数的个数 小于样本数
小于样本数 而言,求解对偶问题似乎并不有优势。
而言,求解对偶问题似乎并不有优势。
好处是:对偶形式可以使用核函数,因为内积求解非常方便。在高维空间,特征维数远远大于样本数,甚至无穷维空间,这样的好处是显而易见的。
核函数是正定的,这使得 有一个下界,从而使得优化问题well-defined。
有一个下界,从而使得优化问题well-defined。
对于输入样本,根据训练出来的模型预测其输出。
 ,
, 

讨论:b的值没有出现在对偶问题中,利用原始可以找到 。
。
KKT条件

对于每个数据点,要么 ,要么
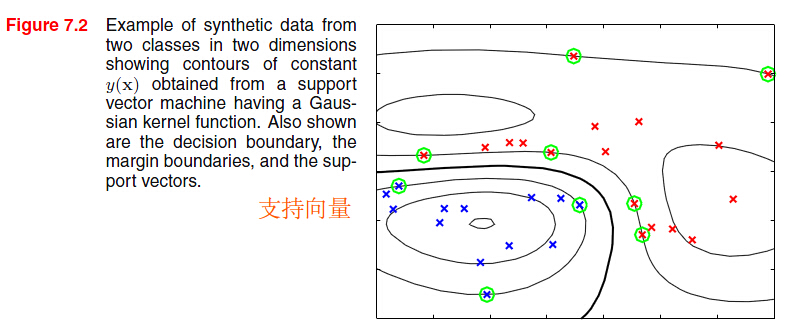
,要么 。 对于的点不会出现在对偶优化问题中,所以对模型参数无作用,对于预测新的输入点无贡献。剩余的数据点称为支持向量(support vectors)。
。 对于的点不会出现在对偶优化问题中,所以对模型参数无作用,对于预测新的输入点无贡献。剩余的数据点称为支持向量(support vectors)。
求解优化问题我们可以得到 向量,并决定阈值(偏置)b的大小。对于任何支持向量
向量,并决定阈值(偏置)b的大小。对于任何支持向量 满足
满足 。
。
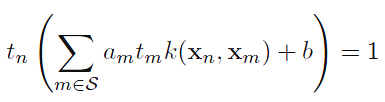
其中 表示支持向量的下标。
表示支持向量的下标。
等式两边乘以 ,使得
,使得 。
。
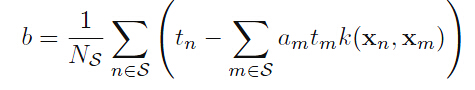
我们可以从损失函数形式来理解SVM,其损失函数即所谓的Hinge Loss。

 为函数,当
为函数,当 时等于0,否则为
时等于0,否则为 。确保约束成立。
。确保约束成立。
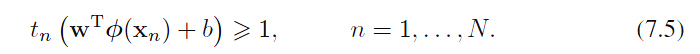
随机梯度下降法(Stochastic Gradient Descent)求解以下的线性SVM模型:

w的梯度为:

传统的梯度下降法需要把所有样本都带入计算,对于一个样本数为n的d维样本,每次迭代求一次梯度,计算复杂度为O(nd) ,当处理的数据量很大而且迭代次数比较多的时候,程序运行时间就会非常慢。
随机梯度下降法每次迭代不再是找到一个全局最优的下降方向,而是用梯度的无偏估计 来代替梯度。每次更新过程为:

由于随机梯度每次迭代采用单个样本来近似全局最优的梯度方向,迭代的步长应适当选小一些以使得随机梯度下降过程尽可能接近于真实的梯度下降法。
LIblinear,官网上是这样介绍的:”LIBLINEAR is a linear classifier for data with millions of instances and features“,即主要专门为百万级别的数据和特征实现的线性分类器。
- 当你面对海量的数据时,这里的海量通常是百万级别以上。海量数据分为两个层次:样本数量和特征的数量。
- 使用线性和非线性映射训练模型得到相近的效果。
- 对模型训练的时间效率要求较高。
http://blog.csdn.net/orangehdc/article/details/38682501
讨论:SVM在高维空间里构建分类器后,为什么这个分类器不会对原空间的数据集Overfitting呢?
第一,SVM求解最优分类器的时候,使用了L2-norm regularization,这个是控制Overfitting的关键。第二,SVM不需要显式地构建非线性映射,而是通过Kernel trick完成,这样大大提高运算效率。
附录:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
clear; load E:\dataset\USPS\USPS.mat; % data format: % Xtr n1*dim % Xte n2*dim % Ytr n1*1 % Yte n2*1 % warning: labels must range from 1 to n, n is the number of labels % other label values will make mistakes u=unique(Ytr); Nclass=length(u); allw=[];allb=[]; step=0.01;C=0.1; param.iterations=1; param.lambda=1e-3; param.biaScale=1; param.t0=100; tic; for classname=1:1:Nclass temp_Ytr=change_label(Ytr,classname); [w,b] = sgd_svm(Xtr,temp_Ytr, param); allw=[allw;w]; allb=[allb;b]; fprintf('class %d is done \n', classname); end [accuracy predict_label]=my_svmpredict(Xte, Yte, allw, allb); fprintf(' accuracy is %.2f percent.\n' , accuracy*100 ); toc; |
|
1 2 3 4 5 6 |
function [temp_Ytr] = change_label(Ytr,classname) temp_Ytr=Ytr; tep2=find(Ytr~=classname); tep1=find(Ytr==classname); temp_Ytr(tep2)=-1; temp_Ytr(tep1)= 1; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
function [true_W,b]=sgd_svm(X,Y,param) % input: % X is n*dim % Y is n*1 (label is 1 or 0) % output: % true_W is dim*1 ,so the score is X*W'+b % b is 1*1 number iterations=param.iterations;%10 lambda=param.lambda;%1e-3 biaScale=param.biaScale;%0 t0=param.t0;%100 t=t0; w=zeros(1,size(X,2)); bias=0; for k=1:1:iterations for i=1:1:size(X,1) t=t+1; alpha = (1.0/(lambda*t)); if(Y(i)*(X(i,:)*w'+bias)<1) bias=bias+alpha*Y(i)*biaScale; w=w+alpha*Y(i,1).*X(i,:); end end end b=bias; true_W=w; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function [accuracy predict_label]=my_svmpredict(Xte, Yte, allw, allb) % allw is nclass * dim % allb is nclass * 1 % Yte must range from 1 to nclass, other label values will make mistakes score = Xte * allw'+repmat(allb',[size(Bte,1),1]); [bb c]=sort(score,2,'descend'); predict_label=c(:,1); temp = predict_label((predict_label-Yte)==0); right=size( temp,1 ); accuracy=right/size(Yte,1); |